 6 May 2026
6 May 2026This page is about a familiy of data compression algorithms from the 1970s. They form the foundation of many of today's compression techniques, such as those found in ZIP, GIF and PNG files. If you read my page on Huffman coding you already know a compression technique. Huffman takes a fixed-size input and encodes it to a variable length output. Lempel-Ziv '77, better known as just LZ77 does the opposite: it encodes a variable length input section with a fixed-length code.
Above you can see LZ77 compression in action: while traversing the input code (at the left) once, the algorithm compares a sliding window behind it (in green) with a lookahead area (in blue) in front of it. If there is a common substring it is referred to by an (offset, length) pair in the output, so that the substring does not have to be encoded twice. So the output of this step contains plain characters from the input, mixed with pairs referring to previous input.
In case you were wondering, the LZ77 algorithm is named for its creators, Abraham Lempel and Jacob Ziv. Expansion or decompression is simpler here than compression. The program simply copies the input characters back to the output, and inserts strings from back-references at the current position. This can be seen above. Note that with this small example we don't get all that much compression. In a real system the sliding windows would be larger, and there would be more opportunity for matches, at the cost of more processing.
LZ78 is the cousin of LZ77 and as the name suggests it was invented a year later. Where LZ77 does local compression within a window, LZ78 goes for global compression by maintaining a table of strings that grows ever larger as the input is processed. Above we now have a table between input and output, which is automatically compiled from the traversal of the input. The output is a series of pairs, a code followed by a character. If the code is zero, it means to just output the character during expansion. At the same time, the character gets an incremental code in the table. If the code in the output is larger than zero, the pair represents that entry in the table followed by the character, and again this new string is given a code in our translation table.
The encoding table grows automatically during compression and decompression and should contain the same codes in both cases. Through this cleverness of the algorithms the table does not need to be stored in the compressed file, which saves a lot of space. The last pair does not have a character and this is the end of the output.
LZ78 expansion is straightforward, but care must be taken to construct the table with the exact same contents as during compression. After outputting a string, it has to be added to our table with the next incremental code assigned to it, like before. A blue background in the table indicates a new addition, while a green background indicates a successful lookup.
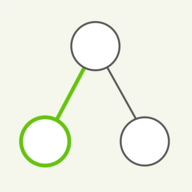
The table that LZ78 builds during compression is essentially a trie. Each node shows the character on the left and its table code on the right. The root node represents the empty prefix with code 0. When a new entry is added, the algorithm traverses the trie from the root to the node of the matching prefix, then attaches a new child for the next character. The trie that is built during compression contains the same information as the table used in decompression. While LZ78 does better at global, file-wide compression than LZ77, it requires more space to keep the trie in memory. Above you can see the trie being built during the encoding of a short string.
LZW is a variant of LZ78 published by Terry Welch in 1984. The key difference is that the table is pre-initialized with all single characters from the input. Because every character is already in the table, LZW never needs to output a raw character — it always outputs a code. Above you can see the table starting with single-character entries, and growing as longer strings are discovered during compression. The output is a sequence of codes, each referring to a table entry. We show the data structure as a table here, but as with LZ78 for compression it is implemented as a trie.
LZW expansion rebuilds the table from the stream of codes. The decoder starts with the same initial single-character table as the encoder. For each code received, it looks up the corresponding string and outputs it. At the same time, it adds a new table entry formed by the previous output string plus the first character of the current one. This way the decoder reconstructs the exact same dictionary that the encoder built, without needing it to be stored in the compressed data.
We have seen three classic compression methods on this page, each rather simple in its original formulation. But between them they are the ancestors of many modern file and stream compressions.
The Claude Opus LLM helped create this page. There are more algorithms and data structures to be found on the main page.
Please consider sharing this site on social media!