 30.04.2026
30.04.2026Die einfachste Art, eine deutsche Zeichenkette zu kodieren, ist jedes Zeichen einzeln in einen Binärcode zu übersetzen und diese aneinanderzureihen. Ein klassischer Code für Englisch ist ASCII, der Zeichen ursprünglich in 7 Bits kodierte. Im obigen Diagramm verwenden wir 8 Bits für eine bessere Byte-Ausrichtung und damit wir auch Umlaute kodieren können, die in ASCII nicht enthalten sind. Man sieht, wie die kurze Zeichenkette links in Binärcode übersetzt wird.
Mit derselben Codetabelle kann der Binärcode zurück ins Deutsche übersetzt werden, indem jeder Code nachgeschlagen wird, der einen Buchstaben darstellt. Dieser Ansatz verschwendet allerdings Speicherplatz. Zum einen hat das lateinische Alphabet nur 26 Buchstaben, aber mit 8 Bits können wir 256 verschiedene Zeichen darstellen. Außerdem möchten wir Codes variabler Länge verwenden, bei denen häufige Buchstaben eine kurze Binärdarstellung erhalten und seltene eine längere. Das bringt uns zu Huffman.
Huffman-Codes sind nach ihrem Erfinder David Huffman aus den USA benannt. Sie sind eine Form der präfixfreien Kodierung mit variabler Länge, die auf einem Baumalgorithmus basiert. Präfixfrei bedeutet, dass kein Zeichencode der Präfix eines anderen ist, was die Kodierung mehrdeutig machen würde. Mehr dazu erfahren sie weiter unten auf dieser Seite. Der erste Schritt bei der Huffman-Kodierung ist das Zählen der Häufigkeit jedes zu kodierenden Zeichens. Oben kann man dies in Aktion sehen.
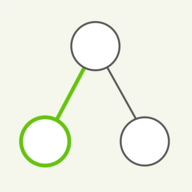
Der nächste Schritt nach dem Zählen ist der Aufbau eines Baums. Wir beginnen mit jedem Zeichen in einem separaten Blattknoten zusammen mit seiner Häufigkeit. Die zwei kleinsten Knoten nach Häufigkeit werden unter einem gemeinsamen inneren Elternknoten zusammengeführt, der mit der Summe der Häufigkeiten annotiert wird. Gleichstände bei der Häufigkeit können beliebig aufgelöst werden. Nach und nach entsteht ein Binärbaum, dessen Blattknoten jeweils ein Zeichen darstellen. Jede Kante unter einem inneren Knoten wird danach eindeutig mit 0 oder 1 beschriftet, wie oben zu sehen ist.
Zur Kodierung einer Zeichenkette wandeln wir den Baum in eine Tabelle um, die Buchstaben auf Binärcodes abbildet, wie oben zu sehen ist. Dazu durchlaufen wir den gesamten Baum und merken uns die Bits auf den Kanten. Jedes Mal, wenn ein Blattknoten erreicht wird, bestimmt der Pfad von der Wurzel die Binärdarstellung dieses Zeichens.
Der letzte Schritt der Kodierung ist die Übersetzung wie zuvor, aber mit unserer Huffman-Tabelle anstelle von ASCII. Hier hat jeder Code eine unterschiedliche Bitlänge, aber insgesamt benötigen wir weniger Bits für die Zeichenkette. In diesem Sinne ist die Huffman-Kodierung nachweislich optimal.
Um die Binärzeichenkette zurück in Text zu dekodieren, verwenden wir den Huffman-Baum direkt. Beginnend an der Wurzel lesen wir Bit für Bit: eine 0 bedeutet nach links, eine 1 bedeutet nach rechts. Wenn ein Blattknoten erreicht wird, haben wir ein dekodiertes Zeichen gefunden und geben es aus. Dann kehren wir zur Wurzel zurück und wiederholen den Vorgang. Da Huffman-Codes präfixfrei sind, ist die Dekodierung eindeutig — es gibt immer genau eine Möglichkeit, den Bitstrom in Zeichen zu zerlegen.
Was wir hier ausgelassen haben ist, dass der Huffman-Baum ebenfalls kodiert und dem Binärcode vorangestellt werden muss. Ohne ihn ist die korrekte Dekodierung unmöglich. Dafür gibt es weitere Algorithmen, die wir auf dieser Seite nicht illustrieren. Daher ist Huffman-Kodierung nicht immer die allerbeste Wahl.
Das Claude Opus LLM hat bei der Erstellung dieser Seite geholfen. Weitere Algorithmen und Datenstrukturen finden sich auf der Hauptseite.
Bitte teilt diese Seite auf Social Media!